公開日: 2010年08月12日(Thu)
社内イントラネットワークで使える全文検索エンジンの『どこかな?』 を試してみる。
『どこかな?』の大まかな特徴を挙げてみると、次のような感じかな。
やってみないとわからないので、セットアップして実際に動かしてみる。
結論から言うと、かなりドキュメントに乏しい印象で、いろいろ調べていってもわからないことが多かったし、試したバージョン0.5.0でウェブの全文検索はできなかった。なのでこの記事は、手順とかをまとめるというよりは、奮闘期的な記録記事になった。
今回はお試しなので、VMware×Ubuntuの使い捨て環境を利用して、そこで動かしてみる。
UbuntuはDebian系らしいので、使うパッケージはたぶん *.deb というやつ。
まず、適当な一時ディレクトリを作って、そこで作業することにする。
# cd
# mkdir inst
# cd inst
パッケージはSOURCEFORGE.JPからダウンロードできる。姉妹ツールである『しゃべる』と同じ画面になっているが、shovelじゃなくてdokoが『どこかな?』なので注意。今回はDebian系なので doko_0.5.0-1_i386.deb を入手すればいい。今回の手順では、wgetを使ってコマンドラインでダウンロードすることにする。
debパッケージのインストール方法について、http://www.ep.sci.hokudai.ac.jp/~epcore/dvlop/y2001/package.html の『3. dpkg を用いる場合』を参考にやってみる。
そして、wgetコマンドでdebパッケージをダウンロード。
# wget "http://sourceforge.jp/frs/redir.php?m=osdn&f=%2Fshovel%2F32236%2Fdoko_0.5.0-1_i386.deb"
インストール。
# sudo dpkg --install "doko_0.5.0-1_i386.deb"
すると、下記のような短いログが表示されて、簡単にインストールが完了した。
未選択パッケージ doko を選択しています。
(データベースを読み込んでいます ... 現在 99528 個のファイルとディレクトリがインストールされています。)
(doko_0.5.0-1_i386.deb から) doko を展開しています...
doko (0.5.0-1) を設定しています ...
Install Finished. Let's enjoy!!
Access URL: http://ubuntu-vm:8080/
Access URL: http://ubuntu-vm:8080/
と言われているのでFirefoxでアクセスしてみると、いきなり検索画面のトップページが表示された。
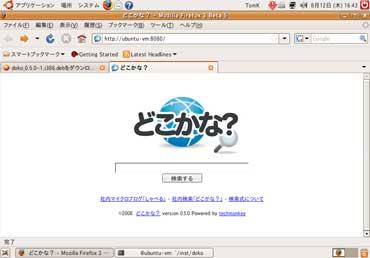
え、設定とかなし? ポート番号8080は問答無用で固定なのかしら?
とりあえず、何の設定もできないというわけはないので、やり方を探してみる。が、ドキュメントもFAQも空っぽなようだ・・・。
トップページを読むと、いつかヒントになりそうなことが読み取れる。
# sudo /etc/init.d/dokod start# sudo /etc/init.d/dokod stop# sudo /etc/init.d/dokod status
よくある再起動のコマンド restart は使えないようだ。
もうひとつ読み取れるのは下記。
インストールしたらまず「しゃべる」のクローリング先のURLを設定してください。
Windowsの場合は、コントロールパネルから「doko」のサービスを停止した後、「インストールディレクトリ/application/shared/classes/shovel.properties」のfetcher.getDatasのXXXXXの部分を「しゃべる」がインストールされているサーバーに変更してください。(ポート番号が8080でない場合はそこも変更してください。)
Windows版では インストールディレクトリ/application/shared/classes/shovel.properties
に何かが置かれているようだ。セットアップがフルオートだったので、インストールディレクトリがどこかわからない。仕方がないから、文字列 「doko」 を含むファイルやディレクトリを find して探してみた。
/usr/doko/には、application と jre というフォルダがある。さらに application の中には、shared, conf, webapps などのフォルダが並んでる。これがインストールディレクトリに違いない。
ちなみに /usr/share/doc/doko/ の方は、ドキュメントかと思って期待したけど、あんまり有用な情報は入ってなさそう。残念。
さて、もとの設定の話に戻ろう。
「インストールディレクトリ/application/shared/classes/shovel.properties」のfetcher.getDatasのXXXXXの部分を「しゃべる」がインストールされているサーバーに変更してください。
このファイルを開いて、まずはその通りに編集してみよう。
# sudo vi /usr/doko/application/shared/classes/shovel.properties
すると、該当の行のデフォルトは下記のようになっていた。
fetcher.getDatas=http://XXXXX:8080/statuses/public_timeline.xml
public_timeline.xml? 要するに、『しゃべる』のタイムラインを検索するための設定なようだ。でも今回やりたいことはそれではないので、普通のウェブページのURLを指定してみることにした。
次のように書き換えて保存して閉じる。
fetcher.getDatas=http://*********.jp/index.html
URLは実在する適当なサイトの適当なHTMLページ。お試しなので、他人に迷惑のかからないページを選ぶこと。
保存したら『どこかな?』を再起動。
# sudo /etc/init.d/dokod stop
# sudo /etc/init.d/dokod start
記載によると 設定終了後、「doko」のサービスを開始すれば、クローリングが開始され、しばらくすると検索可能になります。初期値では、クローリングが3分に1回、100件ずつ行い、転置インデックスの再読み込みは90秒になっています。
とあるので、このままほっとけばクロールが始まって、検索サービスが使えるようになるようだ。
・・・が、やっぱり検索はできるようにならなかった。
たぶん、『しゃべる』が生成する public_timeline.xml の形式を読み込む機能しか実装されていないのではないかな。
ドキュメントに記載はないが、/usr/doko/application/conf/ にも設定っぽいディレクトリがあるので開いてみたが、関係ありそうな設定ファイルは見当たらなかった。
Catalina とか tomcat-users.xml とかが入っているので、Java言語を知っている人ならいじくり方が解るのかも知れない。
結果として、現在のところ(バージョン0.5.0)、普通のウェブ検索に使えるようにはなっていないんじゃないか、と思う。
という前提でもう一度トップページをよく見ると、
インストールにあたっての注意事項。「しゃべる」のバージョンが、0.9.6以上でないと動作しません。
と書いてあるのは、本当にそういうことだったんだな、って。
MOONGIFTさんが Web上の情報向けの全文検索エンジンとして、こちらを紹介しよう。
って言ってたからできそうかな、って思ったのに。残念。
ということで、今回の調査はここまで。
今後の進化に期待です。
公開日: 2010年08月12日(Thu)
