公開日: 2014年03月15日(Sat)

ちなみにこちらは上野動物園のカピバラさん
ウェブページのキャプチャ、とりたいことってありますよね。しかもたくさん。
たくさんページのデザインを確認したいとか、校正するために印刷したいとか、議論しながらメモをしていきたいとか、大きなウェブサイトを作るお仕事ではよくあることです。でも、1ページ1ページ丁寧にキャプチャをとっていったら、時間がかかって大変です。
ということで、今回は、コマンドラインでウェブページのキャプチャ画像を作成してくれるライブラリ capybara-webkit を使ってみました。
他のツールとかちょっとしたスクリプトと組み合わせて使ったら、たくさんのウェブページでも一気にキャプチャ画像を作成できそうです。
主に次のサイトなどを参考にやってみることにします。
Mac OS X 10.8.5 です。下記を実行して、capybara-webkit をインストールします。
$ brew install qt
$ sudo gem install capybara-webkit
qt という何かを先にインストールしているようです。詳しくはわかりませんが、たぶんカピバラさんが使う何かでしょう。これのことかな?
普通はこれだけでインストールは終わりだそうです。が、わたしの環境では、いきなりエラーがおきてカピバラさんのインストールに失敗してしまいました。
Fetching: mini_portile-0.5.2.gem (100%)
Successfully installed mini_portile-0.5.2
Fetching: nokogiri-1.6.1.gem (100%)
ERROR: Error installing capybara-webkit:
nokogiri requires Ruby version >= 1.9.2.
nokogiri は Ruby のライブラリです。おそらくカピバラさんが利用しているものです。 これがRuby 1.9.2 以上を必要としている、とのこと。とりあえずRubyのバージョンを確認してみます。
$ ruby -v
ruby 1.8.7 (2012-02-08 patchlevel 358) [universal-darwin12.0]
Ruby 1.8.7。 なるほど、確かにバージョンが低いですね。ということなので、Rubyのバージョンをあげてみます。
とはいえ、Macにもともと入っている Ruby を直接バージョンアップしてしまうのは、何か起こりそうでちょっとコワイので、今回は RVM というツールを使ってRubyのバージョン管理をします。
$ curl -sSL https://get.rvm.io | bash -s stable
使い方は下記のページを参考にさせていただきました。
今回は、現時点で最新ぽい Ruby 2.1.1 をインストールします。
$ rvm install ruby-2.1.1
Ruby 2.1.1 が RVM に認識されているか確認します。
$ rvm list
rvm rubies
ruby-2.1.1 [ x86_64 ]
# Default ruby not set. Try 'rvm alias create default <ruby>'.
# => - current
# =* - current && default
# * - default
無事、認識されているようです。
ここまででは、新しい Ruby はインストールされたものの、rubyコマンドは古いrubyを参照したままです。これを新しいrubyへ切り替えます。
$ rvm 2.1.1 --default
Warning! PATH is not properly set up, '/Users/tomoya/.rvm/gems/ruby-2.1.1/bin' is not at first place,
usually this is caused by shell initialization files - check them for 'PATH=...' entries,
it might also help to re-add RVM to your dotfiles: 'rvm get stable --auto-dotfiles',
to fix temporarily in this shell session run: 'rvm use ruby-2.1.1'.
RVM is not a function, selecting rubies with 'rvm use ...' will not work.
You need to change your terminal emulator preferences to allow login shell.
Sometimes it is required to use `/bin/bash --login` as the command.
Please visit https://rvm.io/integration/gnome-terminal/ for a example.
うぉ、なんかダメって言われた...。login shell の設定を有効にせよ、と言っているのでしょうか。
いろいろやってみた結果、どうやら私が bash を使ってるのがダメだったようです。一旦 bash から抜けたらできました。
$ exit
$ rvm 2.1.1 --default
ruby コマンドが 2.1.1 に通っているか確認します。
$ ruby -v
ruby 2.1.1p76 (2014-02-24 revision 45161) [x86_64-darwin12.0]
これでOKですね。
さぁ、では、気を取り直してカピバラさんのインストールへ戻ります。
$ gem install capybara-webkit
Fetching: mini_portile-0.5.2.gem (100%)
Successfully installed mini_portile-0.5.2
Fetching: nokogiri-1.6.1.gem (100%)
Building native extensions. This could take a while...
Successfully installed nokogiri-1.6.1
Fetching: xpath-2.0.0.gem (100%)
Successfully installed xpath-2.0.0
Fetching: rack-1.5.2.gem (100%)
Successfully installed rack-1.5.2
Fetching: rack-test-0.6.2.gem (100%)
Successfully installed rack-test-0.6.2
Fetching: mime-types-2.2.gem (100%)
Successfully installed mime-types-2.2
Fetching: capybara-2.2.0.rc1.gem (100%)
IMPORTANT! Some of the defaults have changed in Capybara 2.1. If you're experiencing failures,
please revert to the old behaviour by setting:
Capybara.configure do |config|
config.match = :one
config.exact_options = true
config.ignore_hidden_elements = true
config.visible_text_only = true
end
If you're migrating from Capybara 1.x, try:
Capybara.configure do |config|
config.match = :prefer_exact
config.ignore_hidden_elements = false
end
Details here: http://www.elabs.se/blog/60-introducing-capybara-2-1
Successfully installed capybara-2.2.0.rc1
Fetching: capybara-webkit-1.1.1.gem (100%)
Building native extensions. This could take a while...
Successfully installed capybara-webkit-1.1.1
Parsing documentation for capybara-2.2.0.rc1
Installing ri documentation for capybara-2.2.0.rc1
Parsing documentation for capybara-webkit-1.1.1
Installing ri documentation for capybara-webkit-1.1.1
Parsing documentation for mime-types-2.2
Installing ri documentation for mime-types-2.2
Parsing documentation for mini_portile-0.5.2
Installing ri documentation for mini_portile-0.5.2
Parsing documentation for nokogiri-1.6.1
Installing ri documentation for nokogiri-1.6.1
Parsing documentation for rack-1.5.2
Installing ri documentation for rack-1.5.2
Parsing documentation for rack-test-0.6.2
Installing ri documentation for rack-test-0.6.2
Parsing documentation for xpath-2.0.0
Installing ri documentation for xpath-2.0.0
Done installing documentation for capybara, capybara-webkit, mime-types, mini_portile, nokogiri, rack, rack-test, xpath after 17 seconds
8 gems installed
きた! カピバラさん! 今度は成功です。
それでは、早速ウェブキャプチャを保存してみます。
こちらのページのお手本コードを参考に、ちょっと変更しながら試してみました。
まず、Rubyスクリプトファイルを作成します。名前はなんでもいいですが、ここでは capybaraWebkit.rb ということにします。
$ vim capybaraWebkit.rb
次のコードを実装します。
require 'capybara-webkit'
browser = Capybara::Webkit::Driver.new('web_capture').browser
browser.visit 'http://www.pxt.jp/'
browser.render('pxt.png', 1024, 650)
できたら、rubyコマンドから動かしてみましょう。
$ ruby capybaraWebkit.rb
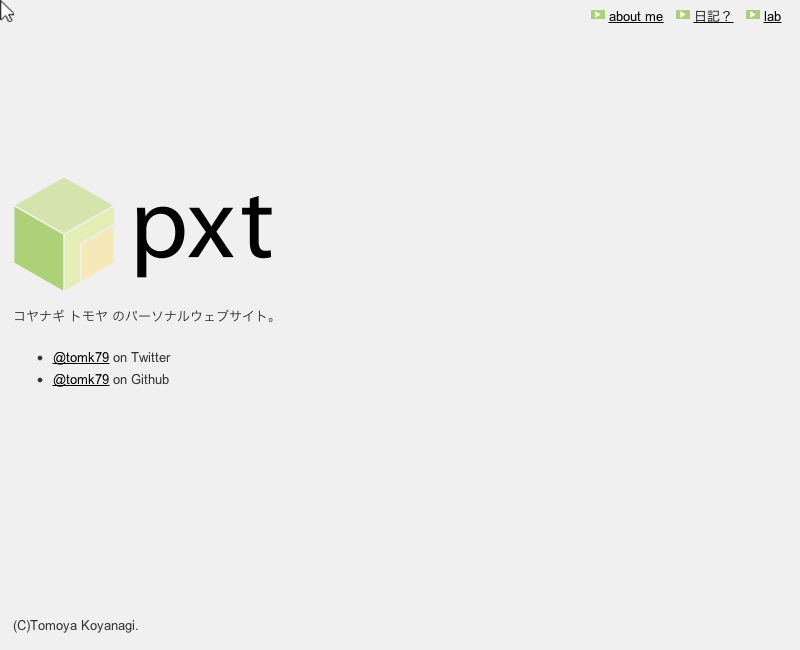
すると、同階層に pxt.png が生成されました。成功!
とれた画像はこちらです。

幅1024px、高さ650pxのPNG画像です。第2、第3引数が画像のサイズを指定しているようです。
画面の左上にマウスポインタが写っているのがやや気になりますね。これ、消せないのかな?
少ないですが、先ほどのコードのパラメータについて見てみます。
browser.visit 'http://www.pxt.jp/'
ここで、キャプチャを作成したいページのURLを設定します。
browser.render('pxt.png', 1024, 650)
この部分で実際にキャプチャ画像を生成しています。
render() メソッドの第1引数は、キャプチャ画像の保存先のパス、第2引数はブラウザのウィンドウ幅、第3引数はウィンドウの高さを設定します。第3引数を設定しても、ウェブページがこの高さに収まらなければ、全体がキャプチャされ、縦に長ーーーーーい画像が得られます。
これをいじくって、たとえばこういうふうにすると、レスポンシブ・デザインのキャプチャを撮影することもできたりするわけですね。
require 'capybara-webkit'
browser = Capybara::Webkit::Driver.new('web_capture').browser
browser.visit 'http://www.pxt.jp/'
browser.render('pxt_l.png', 1024, 650)
browser.render('pxt_m.png', 800, 650)
browser.render('pxt_s.png', 320, 650)


というわけで、カピバラさんの基本はわかったんじゃないか、と思います。
あともし、USER_AGENTを変更してのキャプチャとか、onloadから数秒おいての時間差キャプチャとか、画像オフ、JavaScriptオフなどの条件でキャプチャができたりすると、いろいろ夢が広がりそうです。できるのかな?
でも、それはまた次の機会に調べてみたいと思います。
公開日: 2014年03月15日(Sat)
